
LLM models are gaining traction with their use cases expanding across a wide range of domains. But most of us may never have thought about how these AI models work or how much memory they require.
Well, the memory is, of course, massive to store Key-Value (KV) data, data in their KV cache, and more. Fortunately, Google Research has introduced TurboQuant, a compression algorithm that reduces memory issues in vector quantization while improving its speed and accuracy.
Alongside this, the tech giant also introduced PolarQuant and Quantized Johnson-Lindenstrauss (QJL), which utilize the power of TurboQuant to deliver the results. All the models aim to redefine AI performance using the compression method, which takes up less space while maintaining accuracy, as confirmed by the researchers. Let’s know more details about Google’s newly introduced algorithms meant for the AI good.
The Early Challenges with Vector Quantization
Vector quantization is a traditional compression technique that reduces high-dimensional data to a smaller size. It is an important concept in AI systems that boosts speed and efficiency. Alongside, reduces the pressure on the key-value cache, an important part of modern inference, by compressing the data it stores and enabling quick processing with less memory.
This vector quantization has a downside. They frequently need to store more parameters in full precision when using smaller data chunks. This results in additional memory overhead, which typically adds a few bits per value, undermining its actual benefits.
What is TurboQuant: The Emergence
When you have a long conversation with the AI chatbot, it needs to remember everything that was said before. It stores everything in the key-value cache. Now here comes TurboQuant, a compression method that reduces the size of the key-value (KV) cache without compromising accuracy or speed.
To put it simply, TurboQuant aims to compress AI models with no preprocessing data. It allows AI systems to operate devices with minimal hardware. On some benchmarks, Google’s TurboQuant showed an 8x performance increase and a 6x reduction in memory usage without quality loss.
Here is the official release statement by Google Research on X:
 The following are the stages of TurboQuant:
The following are the stages of TurboQuant:
Stage 1: In this step, TurboQuant uses PolarQuant to rotate data vectors randomly and convert Cartesian to polar coordinates. This step simplifies the data structure, so it can be easily compressed using a standard quantizer that converts detail values into easy numbers. Most of the compression occurs in this step, the fundamental process by which neural networks determine which data is crucial.
Stage 2: Here, it applies Quantized Johnson-Lindenstrauss (QJL) with 1 bit to correct the smallest error left in the first stage. It serves as a mathematical error-checker that eliminates bias in attention scores.
How Does TurboQuant Achieve High Compression Without Compromising Accuracy?
According to Google’s new research, TurboQuant combines the two algorithms, including PolarQuant and QJL, to boost compression efficiency.
PolarQuant
A type of quantization method that transforms vectors into polar coordinates using a Cartesian coordinate system. It stands as an extraordinary way to solve the memory overhead issue. Google explains this with an example: “Go 3 blocks East, 4 blocks North, with ‘Go 5 blocks total at a 37-degree angle.” PolarQuant separates the radius from an angle, which is two different pieces of information. The changes allow algorithms to compress data without the need for normalization steps.
QJL Algorithm: Less Overhead
The QJL algorithm, also known as the Johnson-Lindenstrauss Transform, compresses large, high-dimensional data into a single-bit representation (+1 or -1). It uses a special estimator to balance the higher-level precision query with lower precision. QJL helps to maintain accuracy while calculating attention scores. Alongside, remove the errors during compression without any additional memory overhead.
Benchmarks Say it All
To showcase its subpar performance, Google tested its algorithmic compression Tools, Needle in Haystack and LongBench. across using benchmarks such as Gemma and Mistral open-source models.
- It delivered high scores across certain tasks while reducing memory usage in the key-value cache by 6x.
- It also went above and beyond the baselines, such as KIVI on LongBench across diverse tasks, including question answering, summarization, and code generation, for all three algorithms.
- The algorithms also performed well on ZeroSCROLLS, RULER, and L-Eval.
- Computing the attention score with 4-bit TurboQuant is 8x faster than 32-bit unquantized keys on GPUH100 accelerators.
Following chart showcases its performance for different tasks:
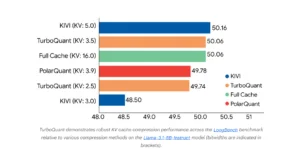
Source: Google Research
Use Cases of TurboQuant on AI Systems:
The following are some of the scenarios wherein TurboQuant can be ideally implemented:
- Search engines that handle billions of vectors
- Support for long-context LLMs
- Make large-scale deployments of AI models such as chatbots, agents, and more scalable and economical
- Real-time recommendation systems
- By reducing memory and computational overhead, TurboQuant enables cost-effective, scalable AI deployments.
Concluding Remarks!
The AI system is growing at the fastest pace. The newly introduced algorithms of TurboQuant, QJL, and PolarQuant are here to reduce the memory use of the AI systems backed by strong theoretical proofs. It reduces memory compression in key-value caches with no compromise in accuracy, addressing one of the bottlenecks in LLM performance.
In addition to other innovations such as PolarQuant and QJL, it showcases how compression techniques that reduce LLM memory usage can lead to faster performance and lower infrastructure costs.
Visit our website to read more informative blog posts around the tech world!
FAQs
1. What is the relationship between PolarQuant and TurboQuant?
Answer: PolarQuant is basically the technique used within TurboQuant. Alongside, it follows a framework that puts together:
- PolarQuant: Handles the key compression through polar transformation.
- QJL: Effectively manages errors through the Johnson-Lindenstrauss transform of 1-bit approximation.
2. What is vector data best used for?
Answer: Vector data is best used in certain scenarios such as detecting fraud, predictive maintenance, navigation and routing, mapping objects, and more.
Recommended For You: