
Suppose you have a master chef who has spent decades in the kitchen. He knows flavors, techniques, and combinations on a huge scale. They can produce sumptuously intricate meals. But think of what this chef might do if they were able to pass on their underlying knowledge, their fundamental “knack,” to a young, gifted chef. The young chef would not have to invest decades of trial and error; they would begin with a profound, intuitive sense, enabling them to produce great food much more rapidly with an easier set of tools. This, in essence, is the heart of a fascinating process in artificial intelligence called AI model distillation.
In the world of AI, we often hear about gigantic models. These are the powerhouses, trained on unimaginable amounts of data. They can write like a human, recognize images with stunning precision, and predict complex patterns. But there’s a catch. Their large size makes them slow, costly to operate, and not suitable for daily use. You wouldn’t employ a supercomputer to switch on your smart lights, would you? That is when there is a need for smaller, more agile versions. But how do we make the smaller version without making it, well, less smart? How do we make it so that it does not lose the precision of its larger version? The secret is in the clever AI model distillation process.
What is Actually Going on During the Distillation Procedure?
Imagine a big, strong AI model as an experienced teacher. This teacher doesn’t have the right answers to the exam, but they know the ins and outs of why those answers are right. They are familiar with the common misunderstandings, the nearly right wrongs, and the entire map of the topic. When this teacher educates a student, they don’t merely provide them with the answer sheet. They impart their rich, subtle knowledge.
In AI model distillation, the teacher is the large model, the “experienced teacher.” The small model we would like to train is the “student.” Rather than only training the student model on raw data, we have it learn from the teacher’s output. But here’s the important bit: we don’t just use the teacher’s final answer.
For instance, if we’re teaching a model to identify animals, the instructor may see a photo of a raccoon and be 98% confident it is a raccoon, 1.5% confident it is a badger, and 0.5% confident it is a cat. This “softer” collection of probabilities, referred to as a “soft label,” holds a lot of information, it displays the relations and proximities between various responses.
The student model picks this deeper information from AI model distillation, mastering the nuances the teacher has learned. This is much better than merely picking up on the fact that the image is “certainly a raccoon.”
This method assures that the distilled, smaller model doesn’t merely replicate the conclusions of the teacher but acquires the thought process of the teacher. This is the key to keeping high accuracy even when the model becomes smaller.
Why Is This So Necessary? The Requirement for Smaller Footprints
The push towards AI model distillation is not an intellectual exercise; it is a real-world necessity. Big AI models are extremely computationally hungry. They need powerful chips and lots of memory, which means high expenses and a great deal of energy usage. Training one big model alone can have the carbon footprint of several cars over their entire lifetimes.
By distilling AI models to make them smaller, we can release intelligent abilities into environments where they were previously out of reach. Your phone is a great example. The voice assistant on your phone, the face recognition camera used for focusing, or the keyboard that anticipates the word you’re about to type; these tend to use distilled models. They must be efficient and operate with an intermittent internet connection to a gigantic cloud server.
As per report, AI model distillation helps smaller models keep 90–95% of the performance of large models, while cutting costs by over 99%. This makes powerful AI tools usable even on phones and low-resource devices.
Difference Between Large Model and AI Distilled Model
Let’s understand the difference between a large model and an AI distilled model:
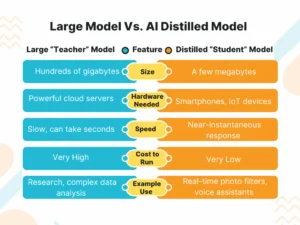
Real World Examples
One of the most familiar examples is language models. You may have used a large language model such as GPT-3 or its successors through a web interface. Such models are intelligent but gigantic. With AI model distillation, companies make these much smaller and able to operate directly on your device. This makes possible features such as advanced predictive typing or document summarization on your computer without having to upload your data to the cloud, which is not only quicker but also better for your privacy.
Another compelling case is in autonomous car tech. The early perception models that detect pedestrians, cars, and signs are vastly sophisticated. But for each millisecond decision a car makes, it can’t possibly wait around for a data center to make its determination. So, AI model distillation is applied to produce highly accurate, smaller models that execute directly on the car’s onboard processors, allowing real-time, life-or-death decisioning.
The Human Touch in a Technical World
It is worth noting that AI model distillation is a tool, and like any tool, its value lies in how we utilize it. The intention is not to replace the big, pathfinding models. They are needed for expanding what is possible. Rather, AI model distillation is about democratizing intelligence. It is about taking those innovative breakthroughs and putting them into a shape that can fit into our pockets, into our homes, and into our daily lives, making technology more responsive, accessible, and efficient for all.
This process is a very human one: the urge to share knowledge, to simplify the complicated, and to make sure that great tools are within everyone’s reach, not only those who possess the largest resources. As we go on improving methods such as AI model distillation, we are working steadily toward a future in which artificial intelligence is no far-off, cloud-soaring enigma, but a friendly, woven, and effective part of our daily lives.
To learn more, visit YourTechDiet!
FAQs
1. How do small AI models attain high accuracy?
Answer: They employ clever training tricks such as distillation and fine-tuning to learn from larger models. This keeps them small but still capable of performing really well on particular tasks.
2. How to reduce AI models in size?
Answer: You can compress models through techniques such as quantization, pruning, and distillation. These save space and accelerate performance without sacrificing much accuracy.
3. How are AI models distilled?
Answer: Distillation is akin to a large model showing a small model how to perform the same task. The little model learns from the large one’s responses and becomes quicker and lighter.
4. What are the four models of AI?
Answer: The four kinds are reactive, limited memory, theory of mind, and self-aware. They vary from straightforward rule-based systems to future AI that can comprehend emotions.
5. Is distillation in AI illegal?
Answer: Distillation itself isn’t against the law, but the use of another company’s model outputs without consent may be. It is all based on how the data is being used and if it violates copyright or the terms of service.
6. Is GPT-4o Mini distilled?
Answer: Yes, GPT-4o Mini is a distillation of the larger GPT-4o model. It is smaller, less expensive, and still good for most tasks.
Recommended For You:
Are Generative AI Models Becoming Commodities or a Core Business Differentiator?
Examining Gemini Nano AI and Its Features: Is It Better than ChatGPT?